protobuf编码基础是Varint, Varint是将一个整数序列化为一个或多个Bytes的方法,这是一种紧凑的表示数字的方法,越小的整数,使用的Bytes越少.
Varint 中的每个 byte 的最高位 bit 有特殊的含义,如果该位为 1,表示后续的 byte 也是该数字的一部分,如果该位为 0,则结束。其他的 7 个 bit 都用来表示数字。因此小于 128 的数字都可以用一个 byte 表示。大于 128 的数字,会用两个字节。
- 每个byte最高位(msb)是标志位,0表示是最后一个byte,1表示该字段值还有后续byte
- 每个byte低7位存放数值
- Varints使用Little Endian(小端)字节序
示例
例如整数1的表示,仅需一个字节:
1
0000 0001
例如300的表示,需要两个字节:
1
1010 1100 0000 0010
下图演示了 Google Protocol Buffer 如何解析两个 bytes。注意到最终计算前将两个 byte 的位置相互交换过一次,这是因为 Google Protocol Buffer 字节序采用 little-endian 的方式。
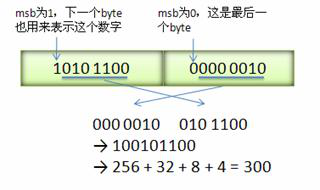
varint 编码
我们还是以数字300为例:
1
2
// 300的二进制
00000001 00101100
然后从字节0的尾部开始,取7位,变成新字节1,并在最高位补1,最高位补1还是0,取决于后面还有没有字节,字节1为:
1
10101100
然后继续在字节0中取7位,标记为字节2,由于这次取完后面已经没有字节了,所以字节2高位为0:
1
00000010
最后,最终编码后的数据变成字节1和字节2的组合:
1
10101100 00000010
varint 解码
再将上面的varint转换回来:首先分析下这段数据,有两个字节,每个字节的最高位只是标记的作用,1代表后面的字节是数字的一部分,0表示这个字节是最后一个字节了,所以去掉各自的最高位,变成:
1
0101100 0000010
然后Varint会将字节调转,变成:
1
0000010 0101100
调转后的数据:256+32+8+4 = 300
以上均为无符号类型,若为有符号类型,Protocol Buffer将会采用ZigZag编码方式。